Construction of a geologic database
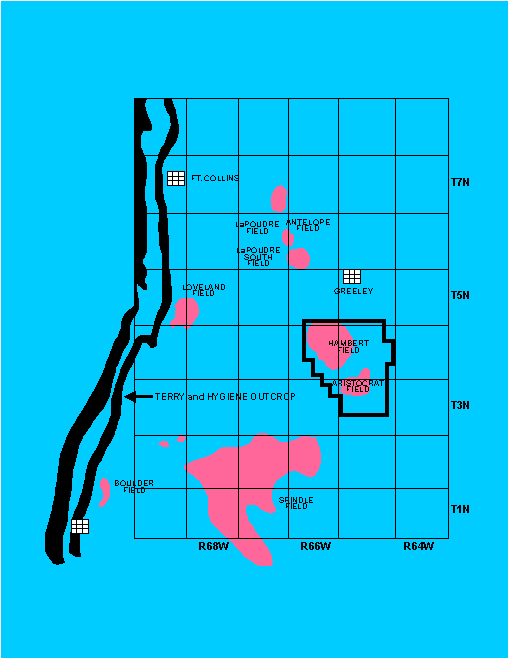
Characterization of oil and gas reservoirs should involve examining geological data beyond the boundaries of the reservoir since stratigraphic and structural features normally are more areally extensive than the geographic area of most reservoirs. We have followed this approach by studying over 1100 wells in 70 sections within T3N-R65W, T4N-R65W, and T4N-R66W (Fig. 1). To evaluate such a large data set, we have developed a methodology for managing these data in a personal computer (PC) environment.
Hierarchy of database development
The methodology involves four hierarchical levels of activity:
- COMPILATION: Identifying the sources of information
- EXTRACTION: Gathering, organizing, and storing data in a manner that allows easy access.
- INTERPRETATION: Processing, describing, translating, comparing, contrasting, classifying, correlating, and calculating data.
- ANALYSIS: Interpreting and synthesizing data into general and specific characterizations that attempt to explain the facts and observations.
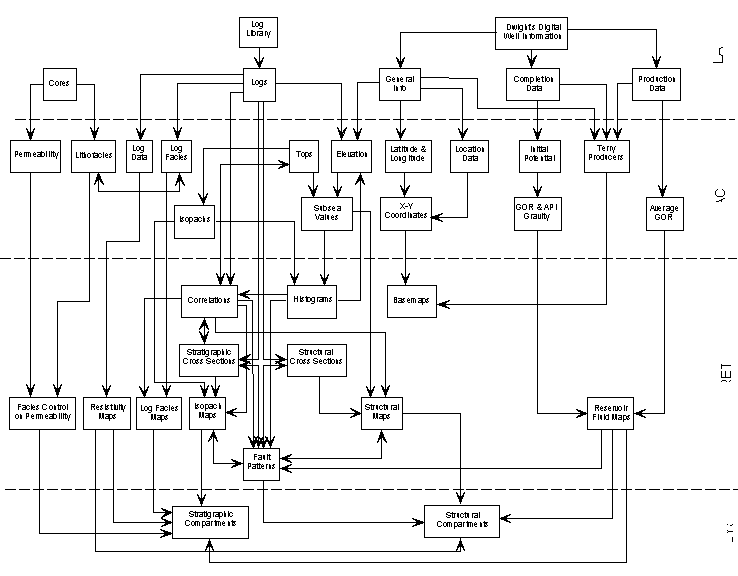
Within this hierarchical framework there are many tasks, sub-tasks, and iterations (Fig. 2). Fundamentally however, the process involves nothing more than a series of information flows (i.e., the results of one task are used in the next). This process is highly non-linear and iterative, and information frequently flows in loops, often more than once. The discussion that follows is meant to be a general guide. The specific steps that one should follow are highly dependent on the nature of the study.
Compilation
The very first step in every reservoir characterization study should be to ask yourself "What do I want to get out of this study?" The answer affects the type of data to compile in the first phase of the methodology. Since each reservoir characterization project tries to answer different questions, each project may need to use a variety of different sources of information. The quality, quantity and types of data available always constrains the ability to answer these questions. Data is expensive and otherwise sometimes difficult to obtain, so often there isn't enough data or the right kinds of data to answer specific questions. Also as a reservoir characterization project proceeds, intermediate results often raise new questions that result in a change in the overall direction of the project.
Our study was designed to assess the degree to which structural and stratigraphic controls create compartments in the Terry Sandstone within the Hambert-Aristocrat field. Thus, the immediate goal was to analyze the distribution of reservoir fluids relative to structural and stratigraphic features. To accomplish this, data needed to be accessed that would provide information on the distribution of reservoir fluids and data that would result in a 3-D image of the structure and stratigraphy of the reservoir. This data was easily obtainable in the form of well log, completion and production data.
Reservoir fluid data is in the form of initial completion (IP, GOR, API gravity, perforations, etc.) and annual production (crude and gas) patterns for Terry producers throughout the study area. The source for this data was Dwight'sTM well history and production CD-ROM's. In addition to these two types of data, the CD-ROM's also supplied basic well information (location, depth, completion date, TD, etc.). There are approximately 1195 wells within the area of interest. Of these, only 208 are Terry producers.
Well logs provide information for stratigraphic correlations that lead to structural and stratigraphic maps and section interpretations, subsurface facies analysis, and pore fluid content. Many operators in the Hambert-Aristocrat area typically run SP-resistivity and gamma ray-density logs. A few wells have other types, including sonic, CNL-FDC, EPT, micro-resistivity, or dipmeter logs. For this study, a complete log suite from at least one well in every quarter-section in the area of interest was copied, including every Terry producer, resulting in a collection of logs from approximately 842 wells.
Different reservoir characterization studies may require accessing other sources of information including core description and conventional and special analysis reports, production tests, drill-stem tests, production logging, source-rock analyses, isotope analysis, thin-section petrography, clay analyses, seismic data, borehole tomography, or gravity, electrical, or magnetic geophysical techniques.
Extraction
This phase involves extracting data from the sources that were compiled in Phase 1. An important aspect of this phase is the choice of recording extracted information. For this study, information was recorded in a series of Excel for Windows™ spreadsheets. The first step in the extraction phase involved downloading approximately 1974 general information and completion records from the Dwight's™ well history CD-ROM into a spreadsheet. Each record represents a unique 'completion' for the wells within the area of interest. These data were manipulated to produce a file that contains a single record for each well, which facilitates mapping. Each well (or line in the database) represents a unique X-Y position on the surface of the earth which also possesses a unique set of stratigraphic horizon data in the third dimension. Detailed completion information is also extracted from the CD-ROM and recorded on this line of data so that it may be correlated with structural and stratigraphic information. The state of Colorado records crude production on a lease basis, rather than on a single well basis, so there is no easy way to correlate production data with individual well history data. This complicates the interpretation of production history for two reasons. First, it is quite common for a single lease with multiple wells to be actually producing from multiple reservoir compartments or zones. Second, the fluid composition of a reservoir changes through time as each well is drilled, produced, and abandoned at different times relative to other wells in the same compartment or zone over the life of the reservoir. For a lease, the production data lists an API number that represents the key well for the lease. However, even if all the wells on a particular lease can be identified, there is no way to proportion the production among the various wells. By knowing which wells are on which lease, data can be plotted at any or all wells on the lease.
As discussed below, GOR data from Dwight's™ production and historical data CD-ROM's were considered critical to evaluating the degree of structural complexity and compartmentalization of the Terry Sandstone in Hambert-Aristocrat field. The initial GOR at the time of completion was extracted from the well history data in one of two ways. Either it was reported in the data or it was calculated by knowing the initial crude/casing head gas or gas/condensate production rates. Since well GOR's may change with time and production, and wells may exhibit erratic early production behavior, the initial GOR's were considered to be unreliable. Therefore, monthly production data was downloaded into an EXCEL spreadsheet and normalized GOR's were calculated on two different ways:
13GOR = Volume of gas produced in the 13th month /Volume of HC liquids produced in the 13th month
Average GOR (AGOR) = Sum of gas produced in months 1-12 /Sum of HC liquids produced in months 1-12
The advantage of the 13GOR is that it represents the GOR for each well in the same way (i.e., normalized) and it removes all erratic early production from the calculation. The disadvantage is that, in any given well, it is possible that the 13th month may not be normal in terms of production. The well may have experienced mechanical difficulties and may have been off-line or throttled back for a period of time. The AGOR smoothes erratic production resulting from these reasons, however early, erratic well behavior influences the AGOR.
Operators usually report tops (depth picks) information which is available on the Dwight's™ CD-ROM. However, these tops may not be reliable for two reasons. First, each operator supplies these tops individually so they may not be internally consistent enough to produce reliable, detailed structural and stratigraphic maps. Second, only major, easily identifiable tops may be recorded so that sufficient detail is not provided to stratigraphically characterize the reservoir interval.
For this study, tops information (depth picks) from about 1035 wells were picked and recorded in an EXCEL spreadsheet. This step illustrates some of the non-linear character of the process involved in constructing this database. In order to pick consistent tops, a correlation scheme must be established for the stratigraphic interval of interest. To do this first involves establishing an informal nomenclature that identifies a series of correlatable horizons present throughout the area. For certain key horizons, such as the Top Terry Sandstone and a bentonite marker beneath the Terry, hereafter termed the D2 Bentonite, it was a relatively straightforward task to identify the picks on individual well logs. However, for some internal stratigraphic markers, identification was much more difficult because the markers are subtle and vary as a function of lateral facies changes. Thus a smaller subset of about 150 wells within the area of interest was used to construct a series of northeast- and northwest-trending stratigraphic cross-sections. Fundamentally, this step involves interpretation of the correlations. Thus, picking tops must be preceded by a certain level of preliminary interpretation and loop tying. When complete, tops were converted into elevations relative to sea level by subtracting them from the kelly bushing elevation in the spreadsheet. Isopachs between all combinations of horizons were also easily calculated in the spreadsheet. The gross shape of the gamma-ray curve was also recorded as a basis for determining a log-shape facies.
With such a large number of wells, it is reasonable to expect that errors will enter into the tops database. Errors or anomalies might result from the following: (1) transcription, typographical, and data entry; (2) incorrect kelly bushing elevations (if an incorrect elevation was suspected, it was compared to a topographic map); (3) deviated wells (if a well was known to be deviated through the Terry interval, it was eliminated from the database); (4) miscorrelations, as mentioned below; and (5) geologic faults which could either result in an anomalously thick or thin section.
The subsea and isopach information in the spreadsheet was examined for, anomalous data in a number of different ways. First, if a horizon's depth value was greater than the value of a stratigraphically higher horizon, it was concluded that there must be an error in one or the other horizon. Second, the database was sorted in ascending order for each horizon, isopach, and elevation columns. The extreme highs and lows in each case were re-examined and verified. A third technique involved constructing frequency histograms for each horizon, isopach, and elevation columns. Any data that appeared in the tails of the distribution were re-examined and verified. Certain isopach histograms proved to be particularly effective for indicating which wells encountered normal faults since these wells typically exhibited anomalously thin isopachs. Deviated wells exhibited anomalously thick isopachs. Some isopach histograms displayed a clear bimodal distribution of data which indicated an inconsistent formation pick.
Interpretation
Although the methodology described above is time-consuming, once the database is built, it is possible to quickly generate maps. The data in the EXCEL spreadsheets can be extracted into ASCII files and read into commercial mapping software packages. Useful maps include information data-postings, production or well test information, log facies codes, isopach and structure maps.
However, routine computer-generated structure-contour and isopach maps are generally not reliable in a geologically complex area because they are contoured in a purely objective manner without the benefit of some geologic knowledge or concept. However, routinely contoured computer-generated maps do serve a purpose in two important ways. First, these maps serve to indicate anomalous or erroneous data, which appear as bulls-eyes on the contours (sinkholes or mounds). Linear trends of these anomalies provide good evidence for faults, while isolated anomalies usually indicate bad data. Second, the structure and isopach maps provide a general indication of structural and stratigraphic trends within the area. Subtle structural or stratigraphic details can also be extracted by computer-generated trend surface, residual, and derivative maps (Varney, 1997).
Analysis
The final phase of the methodology involves the analysis of the items produced during the interpretation phase. During this phase, the results (maps and sections) are synthesized into general and specific characterizations which explain the facts and observations. Furthermore, it is desirable that these characterizations serve as a tool for prediction where the data quantity and quality may not be as good as in the analyzed area. Application of the model to an unknown area thus serves to test the model. Structural and stratigraphic analysis of the Terry Sandstone in the Hambert-Aristocrat area, utilizing the above methods, is discussed below.
{kind=link}
{kind=link}